 点击查看清晰图片....
点击查看清晰图片....
2007-11-24
人类在谷歌搜索中扮演的角色
哈哈,这篇写于2007年6月的文章中的内容包含了不少有趣的新动向,我部分赞同原作者的观点,也希望自己的多年之后还能再看到这篇文章!
发表者:GoogleChinaBlog翻译自 Matt Cutts 个人博客
Randy Stross 为纽约时报写了一个有趣的文章,从人文的角度谈论搜索的问题,而我今天也想要谈谈人(或者说人工或人类)在谷歌搜索中所扮演的角色。
关于这篇博客,你将看到的不是一条免责声明,而是两个。哈哈!免责声明读一赠一。我的免责声明是:
— 这个帖子上完全是我个人的观点(这是我原来一贯的免责条款)
— 我真的十分缺乏睡眠。我上周末去了 Foo Camp,这是我第一去那里,因此我熬通晓直到昨天早上 4 点,和别人交谈,而且发现狼人游戏像毒品一样容易上瘾。言归正传,让我们从一个问题开始。(哈哈!这是赠送的。)
搜索的未来是什么?
我见过一些显而易见的答案。举例来说,谷歌将会继续在搜索的国际化方面加倍努力,力求在日文、德文、阿拉伯文或挪威文搜索上做得像英语一样好。但是,长期目标呢?未来的搜索 -
— 个性化?
— 全新的用户界面?
— 能够从语义角度上理解询问或文件?
— 社会化搜索?(我把它定义为"通过人的力量来改良搜索")
— 整合搜索?(引进非html来源的文件如图像、视频、专利等等)
— 一个上述所有特征的组合,抑或是一种完全不同东西?
谷歌花费了许多时间思考搜索的未来,当然其他人也在思考这个问题。让我们从这样一个领域 ,即社会化搜索入手,进行一番深入的探究吧。
社会化搜索:人的能量如果你向一个普通技术人员询问有关谷歌的问题,他会告诉你,我们使用大量的计算机和算法语言。的确,纽约时报文章的标题就是《人类的介入有可能撬开谷歌的铁钳》。但是(请注意,这是我个人之见),把谷歌单纯当作冷冰冰的算法语言和计算机而没有人类的空间,这是不对的。下面,我举几个例子,证明过去很多年来人在谷歌内部所扮演的角色:
— 网页排名在实质上是与人们在网上建立的超级链接有关。创造链接的那些人也帮助谷歌形成关于网页重要程度的看法;
— 谷歌资讯考察各式各样的新闻来源;数以千计新闻站点的编辑人员所做出的决定恰恰帮助谷歌评估特定新闻故事是否重要;
— 早在 2001 年,谷歌就在工具条上引进了投票按钮。它们看起来像快乐或愁苦的小脸,让普通人将赞成或反对的选票发送给谷歌;
— 谷歌已经允许用户从谷歌提供的结果中删除他们不喜欢的部分;
— 五年多时间里,我们允许用户向谷歌举报作弊网站。几年来我们一直在说,谷歌保留对作弊网站采取人工干预的权力。(举例来说,如果某人输入了自己的姓名,却得到了离题万里的色情结果)
当然,谷歌搜索工程师也不是每天早晨来到谷歌后,整天坐在那里什么事情也不干,而把一切都交给计算机代劳。相反,谷歌研究员和工程师花费整天的时间希望能够获取更加深刻的观察,以指引我们创造下一代搜索。我相信,谷歌搜索的工作方式向来是实用主义的:如果某种方式能改善我们的搜索质量,我们一定会虚心接纳。
我听到你说:"但是 Matt,你现在这么说,难道不是因为 Sproose、Mahalo、iRazoo、Bessed 等人力搜索公司最近见诸报端了吗?"实际上,并非如此。我想,我谈论类似的事物已经有很长一段时间。举例来说,我去年接受了 John Battelle 的一次专访(请加链接),你可以通篇阅读我关于人在搜索中所扮演角色的思考(十分冗长),也可以在这里读几段我曾经说过的话:
我认为,谷歌应该对几乎任何能够改善搜索质量的方式敞开胸怀。让我们跃上 50,000 英尺的高空俯瞰。当聪明人思考谷歌时,他们想的是算法语言,而算法语言的确是谷歌的一个重要组成部份。但算法语言并不是魔法;它们不能像雅典娜从宙斯的脑袋里蹦出来那样在计算机上自动生成。算法语言是由人编写的。人们必须确定算法语言的起点和输入的信息。而且通常情况下,那些信息输入在某些方面也是以人类的贡献为基础的。
因此我认为太多人过分强调"谷歌的算法"这一事实。所谓"一叶障目,不见森林"。在我看来,谷歌追求所有可扩展的有力方法,即便这些方法需要人工干预。使用来自人工劳动的贡献本身并没有什么与生俱来的错误 - 必须记住,这样的数据也是有局限性的。
我相信,自从PageRank发明以后,谷歌已经开始考虑该如何以各种不同方式释放人的能量了。我有资格这样说,因为 5 年多以前,我是如此重视运用社会反馈,以致于亲自编写了有关谷歌工具条投票按钮的 Windows 代码。
2007 年 6 月 26 日更新:尽管这篇博客是我的个人见解,但我从谷歌的其他同事处证实,谷歌的确正打算利用人们的反馈来改善搜索质量。在最近的欧洲媒体日活动上,一名来自《卫报》的记者向 Marissa Mayer 提出了这个话题:
Marissa 说:随着互联网的发展,搜索的需要也在增长。起先,雅虎等网站以目录形式手工罗列网站。现在,既然网络充斥着各种信息,是否又出现了人工干预的必要呢?我是指上周新闻报道中提到的 Mahalo.com 人力搜索引擎。
我预期她会说"不",但她没有。
"眼下网络是如此之大,污染如此之严重,的确需要更加复杂的方法才能对它进行搜索了,"她说。
"直到今天,我们还在依赖自动化,但是我相信未来将会两者共用,梳理自动化和人工智能之间的关系。"
这是其中一个例证。 另一个例证来自 Jason Calacanis,他详细记录了在Foo Camp 的一次会议,碰巧 Larry Page 也参加了:
Larry 说,搜索就是发现内容…,而维基百科发现了一个更好的方法来组织信息。他似乎很喜欢这种同时使用人力、流程和机器的模型。
所以这是另一项证据,表明谷歌正敞开胸怀,寻求可扩展的方法来利用人的力量。
原文链接: http://www.mattcutts.com/blog/the-role-of-humans-in-google-search/
AltaVista: A brief history of the AltaVista search engine
AltaVista, which means "a view from above", was one of the first search engines to achieve major success in the late 1990's. Unfortunately it lost significant market share from its peak years now remains a minor search engine using search index results from Yahoo.
In the spring of 1995, scientists at Digital Equipment Corporation's Research lab in Palo Alto, CA, introduced a new computer system - the Alpha 8400 TurboLaser - which was capable of running database software much faster than competing systems. Using this powerful tool, they devised a way to store every word of every page on the entire Internet in a fast, searchable index.
In order to showcase this technology, a team led by Louis Monier, who was a computer scientist with DEC's Western Research Lab, conceived a full text search engine of the entire web. By August 1995 the new search engine conducted its first full scale crawl of the web, which bought back about ten million pages. In the autumn, DEC decided to move AltaVista beyond the labs and offer it as a public service on the web, to highlight DEC's internet businesses. The company tested the search engine internally for two months, allowing 10,000 employees to put the system through its paces.
On December 15th, 1995, less than six months after the start of the project, AltaVista opened to the public, with an index of 16 million documents. It was an immediate success, with more than 300,000 searchers using the engine on its first day. By the end of 1996 AltaVista was handling 19 million requests per day. AltaVista quickly became a favorite of both casual searchers and information professionals.
It became one of the leading search tools on the web, but started to go into decline with the advent of Google and also changes in the business direction of its owning company. Compaq acquired DEC at the start of 1998 for $9.6 billion and a year later, spun off the search engine as The AltaVista Company, when it was intended to go public during the dot com boom. However, in June 1999, CMGI - an Internet investment company who at the time owned 20% of Lycos - agreed to acquire 83 percent of AltaVista.
AltaVista underwent a relaunch at the end of 2002 and offered a range of search functionality, including image and multimedia search options, plus Babel Fish, the web's first Internet machine translation service that can translate words, phrases or entire Web sites to and from English, Spanish, French, German, Portuguese, Italian and Russian.
In a surprise move, Overture purchased AltaVista in February 2003 for a knockdown price of $140m, compared to its valuation of $2.3bn three years previously. Consequently, when Yahoo purchased Overture at the end of 2003, AltaVista was part of the package and, sadly, is now just a clone of Yahoo, using the same search index and very basic, large font, interface.
谈 Page Rank – Google 的民主表决式网页排名技术
转自GoogleChinaBlog 发表者: 吴军, Google 工程师
大家可能听说过,Google 革命性的发明是它名为 “Page Rank” 的网页排名算法,这项技术彻底解决了搜索结果排序的问题。其实最先试图给互联网上的众多网站排序的并不是 Google。Yahoo!公司最初第一个用目录分类的方式让用户通过互联网检索信息,但由于当时计算机容量和速度的限制,当时的 Yahoo!和同时代的其它搜索引擎都存在一个共同的问题: 收录的网页太少,而且只能对网页中常见内容相关的实际用词进行索引。那时,用户很难找到很相关信息。我记得 1999 年以前查找一篇论文,要换好几个搜索引擎。后来 DEC 公司开发了AltaVista 搜索引擎,只用一台 ALPHA 服务器,却收录了比以往引擎都多的网页,而且对里面的每个词进行索引。AltaVista 虽然让用户搜索到大量结果,但大部分结果却与查询不太相关,有时找想看的网页需要翻好几页。所以最初的 AltaVista 在一定程度上解决了覆盖率的问题,但不能很好地对结果进行排序。
Google 的 “Page Rank” (网页排名)是怎么回事呢?其实简单说就是民主表决。打个比方,假如我们要找李开复博士,有一百个人举手说自己是李开复。那么谁是真的呢?也许有好几个真的,但即使如此谁又是大家真正想找的呢?:-) 如果大家都说在 Google 公司的那个是真的,那么他就是真的。
在互联网上,如果一个网页被很多其它网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。这就是 Page Rank 的核心思想。 当然 Google 的 Page Rank 算法实际上要复杂得多。比如说,对来自不同网页的链接对待不同,本身网页排名高的链接更可靠,于是给这些链接予较大的权重。Page Rank 考虑了这个因素,可是现在问题又来了,计算搜索结果的网页排名过程中需要用到网页本身的排名,这不成了先有鸡还是先有蛋的问题了吗?
Google 的两个创始人拉里•佩奇 (Larry Page )和谢尔盖•布林 (Sergey Brin) 把这个问题变成了一个二维矩阵相乘的问题,并且用迭代的方法解决了这个问题。他们先假定所有网页的排名是相同的,并且根据这个初始值,算出各个网页的第一次迭代排名,然后再根据第一次迭代排名算出第二次的排名。他们两人从理论上证明了不论初始值如何选取,这种算法都保证了网页排名的估计值能收敛到他们的真实值。值得一提的事,这种算法是完全没有任何人工干预的。
理论问题解决了,又遇到实际问题。因为互联网上网页的数量是巨大的,上面提到的二维矩阵从理论上讲有网页数目平方之多个元素。如果我们假定有十亿个网页,那么这个矩阵 就有一百亿亿个元素。这样大的矩阵相乘,计算量是非常大的。拉里和谢尔盖两人利用稀疏矩阵计算的技巧,大大的简化了计算量,并实现了这个网页排名算法。今天 Google 的工程师把这个算法移植到并行的计算机中,进一步缩短了计算时间,使网页更新的周期比以前短了许多。
我来 Google 后,拉里 (Larry) 在和我们几个新员工座谈时,讲起他当年和谢尔盖(Sergey) 是怎么想到网页排名算法的。他说:"当时我们觉得整个互联网就像一张大的图 (Graph),每个网站就像一个节点,而每个网页的链接就像一个弧。我想,互联网可以用一个图或者矩阵描述,我也许可以用这个发现做个博士论文。" 他和谢尔盖就这样发明了 Page Rank 的算法。
网页排名的高明之处在于它把整个互联网当作了一个整体对待。它无意识中符合了系统论的观点。相比之下,以前的信息检索大多把每一个网页当作独立的个体对待,很多人当初只注意了网页内容和查询语句的相关性,忽略了网页之间的关系。
今天,Google 搜索引擎比最初复杂、完善了许多。但是网页排名在 Google 所有算法中依然是至关重要的。在学术界, 这个算法被公认为是文献检索中最大的贡献之一,并且被很多大学引入了信息检索课程 (Information Retrieval) 的教程。
How to rip a DVD: A Tutorial
Posted in Computers & Technology, Movies, Law, P2P by Elliott Back on December 26th, 2005. I change the Step 2 in case of it's more suit to our perpose what's to rip chapter from our disk.
Ripping a DVD to xvid or divx avi is really quite easy, if you have the right tools. You’ll first need to download DVD decrypter and auto gordian knot (autogk). DVD decrypter allows you to rip the raw DVD video and audio data off of your disk drive, decrypt the CSS protection, and finally remove any other protection schemes, such as Macrovision. AutoGK is a package of codecs and a GUI interface that will take the raw DVD data through an AV processing pipeline to produce a single windows video file.
Step 1: RIP
Put in a DVD and launch DVD Decrypter. Choose IFO (Information File) mode:

Now make sure you’ve selected a destination for your files:
 Now you need to find which program chain to rip (PGC). Pick the one that’s the longest, or in the case of a TV dvd, the episode you want to rip:
Now you need to find which program chain to rip (PGC). Pick the one that’s the longest, or in the case of a TV dvd, the episode you want to rip:
 Everything’s set up. Just click the green arrow and wait about twenty minutes, after which you will have a set of files which look like this:
Everything’s set up. Just click the green arrow and wait about twenty minutes, after which you will have a set of files which look like this:
VTS_01_0.IFO
VTS_01_PGC_07 - Stream Information.txt
VTS_01_PGC_07_1.VOB
The whole ripping process shouldn’t take more than 5 minutes.
Step 2: ENCODE
I rewrite this step on my own way in case of it can more suit our perpose.If you want to read the original contents.Please browse the author's blog:Elliott C. Back
It's convenient to change the chapter into another format.
I use WinAVI 8.0 to change it into an Avi file which is encode by Xvid MPEG-4 Codec,My perpose is to change a MTV into a 320*240 movie file in case of my cellphone can play it well.You know,I can'tse a computer in my dorm.
By the way.I found it's also have a good looked quility on 320/240 even if your file with only 110Kbps.
So let's begin,Open the WinAVI 8.0.and you'll find a friendly Window click the avi bottom,then select your file.
In the detail setting window you can use some default setting to change your movies.
but we need some special setting,click the Advance bottom you can see some detail setting .Just select what you need. and then ,start change!
Step 3: WATCH
You’re done. Delete all the non .avi files and enjoy the fruits of your ripping.
2007-11-15
Distributed Computing: An Introduction
By Leon Erlanger
Original Link:http://www.extremetech.com/article2/0%2C1697%2C11769%2C00.asp
You can define distributed computing many different ways. Various vendors have created and marketed distributed computing systems for years, and have developed numerous initiatives and architectures to permit distributed processing of data and objects across a network of connected systems.
One flavor of distributed computing has received a lot of attention lately, and it will be a primary focus of this story--an environment where you can harness idle CPU cycles and storage space of tens, hundreds, or thousands of networked systems to work together on a particularly processing-intensive problem. The growth of such processing models has been limited, however, due to a lack of compelling applications and by bandwidth bottlenecks, combined with significant security, management, and standardization challenges. But the last year has seen a new interest in the idea as the technology has ridden the coattails of the peer-to-peer craze started by Napster. A number of new vendors have appeared to take advantage of the nascent market; including heavy hitters like Intel, Microsoft, Sun, and Compaq that have validated the importance of the concept. Also, an innovative worldwide distributed computing project whose goal is to find intelligent life in the universe--SETI@Home--has captured the imaginations, and desktop processing cycles of millions of users and desktops.
Increasing desktop CPU power and communications bandwidth have also helped to make distributed computing a more practical idea. The numbers of real applications are still somewhat limited, and the challenges--particularly standardization--are still significant. But there's a new energy in the market, as well as some actual paying customers, so it's about time to take a look at where distributed processing fits and how it works.
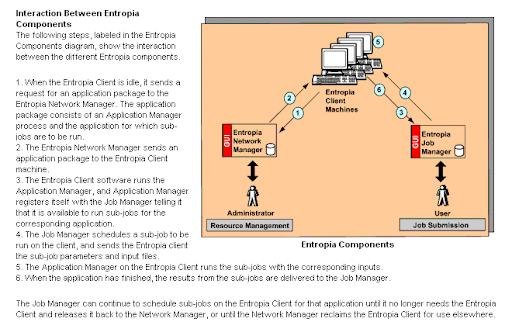
Distributed vs Grid Computing
There are actually two similar trends moving in tandem--distributed computing and grid computing. Depending on how you look at the market, the two either overlap, or distributed computing is a subset of grid computing. Grid Computing got its name because it strives for an ideal scenario in which the CPU cycles and storage of millions of systems across a worldwide network function as a flexible, readily accessible pool that could be harnessed by anyone who needs it, similar to the way power companies and their users share the electrical grid.
Sun defines a computational grid as "a hardware and software infrastructure that provides dependable, consistent, pervasive, and inexpensive access to computational capabilities." Grid computing can encompass desktop PCs, but more often than not its focus is on more powerful workstations, servers, and even mainframes and supercomputers working on problems involving huge datasets that can run for days. And grid computing leans more to dedicated systems, than systems primarily used for other tasks.
Large-scale distributed computing of the variety we are covering usually refers to a similar concept, but is more geared to pooling the resources of hundreds or thousands of networked end-user PCs, which individually are more limited in their memory and processing power, and whose primary purpose is not distributed computing, but rather serving their user. As we mentioned above, there are various levels and types of distributed computing architectures, and both Grid and distributed computing don't have to be implemented on a massive scale. They can be limited to CPUs among a group of users, a department, several departments inside a corporate firewall, or a few trusted partners across the firewall.
How It Works
In most cases today, a distributed computing architecture consists of very lightweight software agents installed on a number of client systems, and one or more dedicated distributed computing management servers. There may also be requesting clients with software that allows them to submit jobs along with lists of their required resources.
An agent running on a processing client detects when the system is idle, notifies the management server that the system is available for processing, and usually requests an application package. The client then receives an application package from the server and runs the software when it has spare CPU cycles, and sends the results back to the server. The application may run as a screen saver, or simply in the background, without impacting normal use of the computer. If the user of the client system needs to run his own applications at any time, control is immediately returned, and processing of the distributed application package ends. This must be essentially instantaneous, as any delay in returning control will probably be unacceptable to the user.
Distributed Computing Management Server
The servers have several roles. They take distributed computing requests and divide their large processing tasks into smaller tasks that can run on individual desktop systems (though sometimes this is done by a requesting system). They send application packages and some client management software to the idle client machines that request them. They monitor the status of the jobs being run by the clients. After the client machines run those packages, they assemble the results sent back by the client and structure them for presentation, usually with the help of a database.
If the server doesn't hear from a processing client for a certain period of time, possibly because the user has disconnected his system and gone on a business trip, or simply because he's using his system heavily for long periods, it may send the same application package to another idle system. Alternatively, it may have already sent out the package to several systems at once, assuming that one or more sets of results will be returned quickly. The server is also likely to manage any security, policy, or other management functions as necessary, including handling dialup users whose connections and IP addresses are inconsistent.
Obviously the complexity of a distributed computing architecture increases with the size and type of environment. A larger environment that includes multiple departments, partners, or participants across the Web requires complex resource identification, policy management, authentication, encryption, and secure sandboxing functionality. Resource identification is necessary to define the level of processing power, memory, and storage each system can contribute.
Policy management is used to varying degrees in different types of distributed computing environments. Administrators or others with rights can define which jobs and users get access to which systems, and who gets priority in various situations based on rank, deadlines, and the perceived importance of each project. Obviously, robust authentication, encryption, and sandboxing are necessary to prevent unauthorized access to systems and data within distributed systems that are meant to be inaccessible.
If you take the ideal of a distributed worldwide grid to the extreme, it requires standards and protocols for dynamic discovery and interaction of resources in diverse network environments and among different distributed computing architectures. Most distributed computing solutions also include toolkits, libraries, and API's for porting third party applications to work with their platform, or for creating distributed computing applications from scratch.
What About Peer-to-Peer Features?
Though distributed computing has recently been subsumed by the peer-to-peer craze, the structure described above is not really one of peer-to-peer communication, as the clients don't necessarily talk to each other. Current vendors of distributed computing solutions include Entropia, Data Synapse, Sun, Parabon, Avaki, and United Devices. Sun's open source GridEngine platform is more geared to larger systems, while the others are focusing on PCs, with Data Synapse somewhere in the middle. In the case of the http://setiathome.ssl.berkeley.edu/ project, Entropia, and most other vendors, the structure is a typical hub and spoke with the server at the hub. Data is delivered back to the server by each client as a batch job. In the case of DataSynapse's LiveCluster, however, client PCs can work in parallel with other client PCs and share results with each other in 20ms long bursts. The advantage of LiveCluster's architecture is that applications can be divided into tasks that have mutual dependencies and require interprocess communications, while those running on Entropia cannot. But while Entropia and other platforms can work very well across an Internet of modem connected PCs, DataSynapse's LiveCluster makes more sense on a corporate network or among broadband users across the Net. 
The Poor Man's Supercomputer
The advantages of this type of architecture for the right kinds of applications are impressive. The most obvious is the ability to provide access to supercomputer level processing power or better for a fraction of the cost of a typical supercomputer. SETI@Home's Web site FAQ points out that the most powerful computer, IBM's ASCI White, is rated at 12 TeraFLOPS and costs $110 million, while SETI@home currently gets about 15 TeraFLOPs and has cost about $500K so far. Further savings comes from the fact that distributed computing doesn't require all the pricey electrical power, environmental controls, and extra infrastructure that a supercomputer requires. And while supercomputing applications are written in specialized languages like mpC, distributed applications can be written in C, C++, etc.
The performance improvement over typical enterprise servers for appropriate applications can be phenomenal. In a case study that Intel did of a commercial and retail banking organization running Data Synapse's LiveCluster platform, computation time for a series of complex interest rate swap modeling tasks was reduced from 15 hours on a dedicated cluster of four workstations to 30 minutes on a grid of around 100 desktop computers. Processing 200 trades on a dedicated system took 44 minutes, but only 33 seconds on a grid of 100 PCs. According to the company using the technology, the performance improvement running various simulations allowed them to react much more swiftly to market fluctuations (but we have to wonder if that's a good thing…).
 Scalability is also a great advantage of distributed computing. Though they provide massive processing power, super computers are typically not very scalable once they're installed. A distributed computing installation is infinitely scalable--simply add more systems to the environment. In a corporate distributed computing setting, systems might be added within or beyond the corporate firewall.
Scalability is also a great advantage of distributed computing. Though they provide massive processing power, super computers are typically not very scalable once they're installed. A distributed computing installation is infinitely scalable--simply add more systems to the environment. In a corporate distributed computing setting, systems might be added within or beyond the corporate firewall.
A byproduct of distributed computing is more efficient use of existing system resources. Estimates by various analysts have indicated that up to 90 percent of the CPU cycles on a company's client systems are not used. Even servers and other systems spread across multiple departments are typically used inefficiently, with some applications starved for server power while elsewhere in the organization server power is grossly underutilized. And server and workstation obsolescence can be staved off considerably longer by allocating certain applications to a grid of client machines or servers. This leads to the inevitable Total Cost of Ownership, Total Benefit of Ownership, and ROI discussions. Another byproduct, instead of throwing away obsolete desktop PCs and servers, an organization can dedicate them to distributed computing tasks.
Distributed Computing Application Characteristics
Obviously not all applications are suitable for distributed computing. The closer an application gets to running in real time, the less appropriate it is. Even processing tasks that normally take an hour are two may not derive much benefit if the communications among distributed systems and the constantly changing availability of processing clients becomes a bottleneck. Instead you should think in terms of tasks that take hours, days, weeks, and months. Generally the most appropriate applications, according to Entropia, consist of "loosely coupled, non-sequential tasks in batch processes with a high compute-to-data ratio." The high compute to data ratio goes hand-in-hand with a high compute-to-communications ratio, as you don't want to bog down the network by sending large amounts of data to each client, though in some cases you can do so during off hours. Programs with large databases that can be easily parsed for distribution are very appropriate.
Clearly, any application with individual tasks that need access to huge data sets will be more appropriate for larger systems than individual PCs. If terabytes of data are involved, a supercomputer makes sense as communications can take place across the system's very high speed backplane without bogging down the network. Server and other dedicated system clusters will be more appropriate for other slightly less data intensive applications. For a distributed application using numerous PCs, the required data should fit very comfortably in the PC's memory, with lots of room to spare.
Taking this further, United Devices recommends that the application should have the capability to fully exploit "coarse-grained parallelism," meaning it should be possible to partition the application into independent tasks or processes that can be computed concurrently. For most solutions there should not be any need for communication between the tasks except at task boundaries, though Data Synapse allows some interprocess communications. The tasks and small blocks of data should be such that they can be processed effectively on a modern PC and report results that, when combined with other PC's results, produce coherent output. And the individual tasks should be small enough to produce a result on these systems within a few hours to a few days.
Types of Distributed Computing Applications
Beyond the very popular poster child SETI@Home application, the following scenarios are examples of other types of application tasks that can be set up to take advantage of distributed computing.
A query search against a huge database that can be split across lots of desktops, with the submitted query running concurrently against each fragment on each desktop.
Complex modeling and simulation techniques that increase the accuracy of results by increasing the number of random trials would also be appropriate, as trials could be run concurrently on many desktops, and combined to achieve greater statistical significance (this is a common method used in various types of financial risk analysis).
Exhaustive search techniques that require searching through a huge number of results to find solutions to a problem also make sense. Drug screening is a prime example.
Many of today's vendors, particularly Entropia and United Devices, are aiming squarely at the life sciences market, which has a sudden need for massive computing power. As a result of sequencing the human genome, the number of identifiable biological targets for today's drugs is expected to increase from about 500 to about 10,000. Pharmaceutical firms have repositories of millions of different molecules and compounds, some of which may have characteristics that make them appropriate for inhibiting newly found proteins. The process of matching all these "ligands" to their appropriate targets is an ideal task for distributed computing, and the quicker it's done, the quicker and greater the benefits will be. Another related application is the recent trend of generating new types of drugs solely on computers.
Complex financial modeling, weather forecasting, and geophysical exploration are on the radar screens of these vendors, as well as car crash and other complex simulations.
To enhance their public relations efforts and demonstrate the effectiveness of their platforms, most of the distributed computing vendors have set up philanthropic computing projects that recruit CPU cycles across the Internet. Parabon's Compute-Against-Cancer harnesses an army of systems to track patient responses to chemotherapy, while Entropia's FightAidsAtHome project evaluates prospective targets for drug discovery. And of course, the SETI@home project has attracted millions of PCs to work on analyzing data from the Arecibo radio telescope for signatures that indicate extraterrestrial intelligence. There are also higher end grid projects, including those run by the US National Science Foundation, NASA, and as well as the European Data Grid, Particle Physics Data Grid, the Network for Earthquake Simulation Grid, and Grid Physics Network that plan to aid their research communities. And IBM has announced that it will help to create a life sciences grid in North Carolina to be used for genomic research.
Porting Applications
The major distributed computing platforms generally have two methods of porting applications, depending on the level of integration needed by the user, and whether the user has access to the source code of the application that needs to be distributed. Most of the vendors have software development kits (SDK's) that can be used to wrap existing applications with their platform without cracking the existing .exe file. The only other task is determining the complexity of pre- and post-processing functions. Entropia in particular boasts that it offers "binary integration," which can integrate applications into the platform without the user having to access the source code.
Other vendors, including Data Synapse, and United Devices, however offer API's of varying complexity that require access to the source code, but provide tight integration and access by the application to the all the security, management, and other features of the platforms. Most of these vendors offer several libraries of proven distributed computing paradigms. Data Synapse comes with C++ and Java software developer kit support. United Devices uses a POSIX compliant C/C++ API. Integrating the application can take anywhere from half a day to months depending on how much optimization is needed. Some vendors also allow access to their own in-house grids for testing by application developers.


Companies and Organizations to Watch
Avaki Corporation
Cambridge, MA Corporate Headquarters
One Memorial Drive
Cambridge, MA 02142
617-374-2500
http://www.avaki.com/
Makes Avaki 2.0, grid computing software for mixed platform environments and global grid configurations. Includes a PKI based security infrastructure for grids spanning multiple companies, locations, and domains.
The DataGrid
Dissemination Office:
CNR-CED
Piazzale Aldo Moro 7
00145 Roma (Italy)
+39 06 49933205
http://www.eu-datagrid.org/
A project funded by the European Union and led by CERN and five other partners whose goal is to set up computing grids that can analyse data from scientific exploration across the continent. The project hopes to develop scalable software solutions and testbeds that can handle thousands of users and tens of thousands of grid connected systems from multiple research institutions.
DataSynapse Inc.
632 Broadway
5th Floor
New York, NY 10012-2614
212-842-8842
http://www.datasynapse.com/
Makes LiveCluster, distributed computing software middleware aimed at the financial services and energy markets. Currently mostly for use inside the firewall. Includes the ability for interprocess communications among distributed application packages.
Distributed.Net
http://www.distributed.net/
Founded in 1997, Distributed.Net was one of the first non-profit distributed computing organizations and the first to create a distributed computing network on the Internet. Distributed.net was highly successful in using distributed computing to take on cryptographic challenges sponsored by RSA Labs and CS Communication & Systems.
Entropia, Inc.
10145 Pacific Heights Blvd., Suite 800
San Diego, CA 92121 USA
858-623-2840
http://www.entropia.com/
Makes the Entropia distributed computing platform aimed at the life sciences market. Currently mostly for use inside the firewall. Boasts binary integration, which lets you integrate your applications using any language without having to access the application's source code. Recently integrated its software with The Globus Toolkit.
Global Grid Forum
http://www.gridforum.org/
A standards organization composed of over 200 companies working to devise and promote standards, best practices, and integrated platforms for grid computing.
The Globus Project
http://www.globus.org/
A research and development project consisting of members of the Argonne National Laboratory, the University of Southern California's Information Science Institute, NASA, and others focused on enabling the application of Grid concepts to scientific and engineering computing. The team has produced the Globus Toolkit, an open source set of middleware services and software libraries for constructing grids and grid applications. The ToolKit includes software for security, information infrastructure, resource management, data management, communication, fault detection, and portability.
Grid Physics Network
http://www.griphyn.org/
The Grid Physics Network (GriPhyN) is a team of experimental physicists and IT researchers from the University of Florida, University of Chicago, Argonne National Laboratory and about a dozen other research centers working to implement the first worldwide Petabyte-scale computational and data grid for physics and other scientific research. The project is funded by the National Science Foundation.
IBM
International Business Machines Corporation
New Orchard Road
Armonk, NY 10504.
914-499-1900
IBM is heavily involved in setting up over 50 computational grids across the planet using IBM infrastructure for cancer research and other initiatives. IBM was selected in August by a consortium of four U.S. research centers to help create the "world's most powerful grid," which when completed in 2003 will supposedly be capable of processing 13.6 trillion calculations per second. IBM also markets the IBM Globus ToolKit, a version of the ToolKit for its servers running AIX and Linux.
Intel
Corporation2200 Mission College Blvd.
Santa Clara, California 95052-8119408-765-8080
http://www.intel.com/
Intel is the principal founder of the Peer-To-Peer Working Group and recently announced the Peer-to-Peer Accelerator Kit for Microsoft.NET, middleware based on the Microsoft.NET platform that provides building blocks for the development of peer-to-peer applications and includes support for location independence, encryption and availability. The technology, source code, demo applications, and documentation will be made available on Microsoft's gotdotnet (www.gotdotnet.com) website. The download will be free. The target release date is early December. Also partners with United Devices on the Intel-United Devices Cancer Research Project, which enlists Internet users in a distributed computing grid for cancer research.
NASA Advanced SuperComputing Division (NAS)
NAS Systems Division Office
NASA Ames Research Center
Moffet Field, CA 94035
650-604-4502
http://www.nas.nasa.gov/
NASA's NAS Division is leading a joint effort among leaders within government, academia, and industry to build and test NASA's Information Power Grid (lPG), a grid of high performance computers, data storage devices, scientific instruments, and advanced user interfaces that will help NASA scientists collaborate with these other institutions to "solve important problems facing the world in the 21st century."
Network for Earthquake Engineering Simulation Grid (NEESgrid)
www.neesgrid.org/
In August 2001, the National Science Foundation awarded $10 million to a consortium of institutions led by the National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign to build the NEESgrid, which will link earthquake engineering research sites across the country in a national grid, provide data storage facilities and repositories, and offer remote access to research tools.
Parabon Computation
3930 Walnut Street, Suite 100
Fairfax, VA 22030-4738
703-460-4100
http://www.parabon.com/
Makes Frontier server software and Pioneer client software, a distributed computing platform that supposedly can span enterprises or the Internet. Also runs the Compute Against Cancer, a distributed computing grid for non-profit cancer organizations.
Particle Physics Data Grid (PPDG)
http://www.ppdg.net/
A collaboration of the Argonne National Laboratory, Brookhaven National Laboratory, Caltech, and others to develop, acquire and deliver the tools for a national computing grid for current and future high-energy and nuclear physics experiments.
Peer-to-Peer Working Group
5440 SW Westgate Drive, Suite 217
Portland, OR 97221
503-291-2572
http://www.peer-to-peerwg.org/
A standards group founded by Intel and composed of over 30 companies with the goal of developing best practices that enable interoperability among peer-to-peer applications.
Platform Computing
3760 14th Ave
Markham, Ontario L3R 3T7
Canada
905-948-8448
http://www.platform.com/
Makes a number of enterprise distributed and grid computing products, including Platform LSF Active Cluster for distributed computing across Windows desktops, Platform LSF for distributed computing across mixed environments of UNIX, Linux, Macintosh and Windows servers, desktops, supercomputers, and clusters. Also offers a number of products for distributed computing management and analysis, and its own commercial distribution of the Globus Toolkit. Targets computer and industrial manufacturing, life sciences, government, and financial services markets.
SETI@Home
http://setiathome.ssl.berkeley.edu/
A worldwide distributed computing grid based at the University of California at Berkeley that allows users connected to the Internet to donate their PC's spare CPU cycles to the exploration of extraterrestrial life in the universe. Its task is to sort through the 1.4 billion potential signals picked up by the Arecibo telescope to find signals that repeat. Users receive approximately 350K or data at a time and the client software runs as a screensaver.
Sun Microsystems Inc.
901 San Antonio Road
Palo Alto, CA 94303
USA
650-960-1300
http://www.sun.com/Sun is involved in several grid and peer-to-peer products and initiatives including its open source Grid Engine platform for setting up departmental and campus computing grids (with the eventual goal of a global grid platform) and its JXTA (short for juxtapose) set of protocols and building blocks for developing peer-to-peer applications.
United Devices, Inc.
12675 Research, Bldg A
Austin, Texas 78759
512-331-6016
http://www.ud.com/
Makes the MetaProcessor distributed computing platform aimed at life sciences, geosciences, and industrial design and engineering markets and currently focused inside the firewall. Also partners with Intel on the Intel-United Devices Cancer Research Project, which enlists Internet users in a distributed computing grid for cancer research.
网格观点:网格计算 —— 下一代分布式计算
本专题来自IBMdeveloperWorks 中国
级别: 初级
Matt Haynos (mph@us.ibm.com), 项目总监,Grid Marketing and Strategy, IBM 2006 年 7 月 20 日
过去有两种主要的需求极大地增长了网格计算的价值。不对称经济使得那些 IT 预算有限的公司只能更加充分地利用现有的计算资产,并通过智能地将有限的资源分配给适当的业务应用程序,才能更加灵活地对迅速变化的市场作出快速的响应。本文是这个 “网格观点” 系列文章的第一篇。在本文中,作者 Matt Haynos 对网格计算和诸如 P2P(端到端)、CORBA、集群计算和分布式计算环境(DCE)之类的分布式计算系统之间的异同进行了简要的分析。
网格计算最近作为一种分布式计算体系结构日益流行,它非常适合企业计算的需求。很多领域都正在采用网格计算解决方案来解决自己关键的业务需求,例如:
金融服务已经广泛地采用网格计算技术来解决风险管理和规避问题。
自动化制造业使用网格解决方案来加速产品的开发和协作。
石油公司大规模采用网格技术来加速石油勘探并提高成功采掘的几率。
随着网格计算的不断成熟,该技术在其他领域技术的应用也会不断增加。
从这个特征定义上来说,网格计算与其他所有的分布式计算范例都有所区别:网格计算的本质在于以有效且优化的方式来利用组织中各种异构松耦合资源,来实现复杂的工作负载管理和信息虚拟化功能。(注意,一个组织可能会跨越很多部门、物理位置等。我们此处使用的是 “组织” 一词的抽象意义。)
上一段提到的特征怎么将网格计算与其他分布式模型区分开来呢?这就是我们在本文中希望解答的问题 —— 我们不是展望网格的未来,而是探索一下网格的起源,并了解网格技术是如何逐渐成熟的,然后阐述网格技术与其他分布式计算解决方案(例如 P2P 和 CORBA)之间的区别。我们将通过对网格概念与最流行的分布式计算解决方案进行对比来探索这个问题。首先,我们来理解一下网格计算的价值。
为什么要进行网格计算?
在过去几年中,随着对自己在信息技术方面投资的重新审视,很多工作公司都得出这样一个结论:最重要的事情是更充分地利用已有的计算资源。因此,利用率的重要性就不断增加。从有限的 IT 预算中榨取更多功能已经很有必要。
另外,分布式企业中出现一个广泛的需求:要求能够将有限的资源智能地 分配给适当的业务应用程序。这种技术为企业提供了一定的灵活性,形式可能是对资源重新进行分发,来解决新的市场问题;也可能是让业务应用程序可以更好地服务于迅速变化的现有客户。
从制造业来看 —— 它们将自己的大部分资源都投入到了利润最高的产品中 —— 工作负载管理的目标是将计算资源分配给最重要的应用程序。我们称之为工作负载优化(workload optimization)。这是一个非常有吸引力的概念,不过它可以表示很多业务转换的挑战。例如,我们如何确定企业中到底是哪些东西构成了组件或组织上最重要的工作呢?
现在,这种概念所产生的潜在生产力和与向工作负载优化转化的趋势相关的商业利益都仍然如此巨大,因此这个概念还不可能被丢弃。网格计算背后的思想是解决平衡和重新分配现有 IT 资源所需要的压力。接下来,我们来看看这些思想和概念的起源。
元计算中的 Khosla
以下引自 “The
Triumph of the
Light”,Scientific American,2001 年 1 月:
Vinod
Khosla,Kleiner Perkins
Caufield and Byers 的投资家,
对将计算机汇集在一起的项目进行了评论,这种汇集可能是一个挨一个的,也可能是在全球分布的。元计算(Khosla 将之定义为网格计算)可以下载
Britney Spears 和 Fatboy Slim,也可以利用天文望远镜所观测的数据来寻找外星生命。Khosla
从这种为业务所采用的将所有机器联合起来使用的网络计算模型中看到了巨大的利益,他说,这就像是载有 1,000
名乘客的喷气式飞机所产生的计算流体力学一样重要.
网格计算的起源
与 Internet 类似,学术机构在开发构成网格计算基础的第一代技术和架构时,也走在了最前面。很多机构,例如 Globus Alliance、China Grid 和 e-Science Grid 核心程序,都是第一批开始孵化并培育网格解决方案使其不断成熟并适用于商业解决方案的地方。
网格诞生于那些非常需要进行协作的研究和学术社区。研究中非常重要的一个部分是分发知识的能力 —— 共享大量信息和帮助创建这些数据的计算资源的效率越高,可以实现的协作的质量就越好,协作级别也越广泛。
在商业领域也存在这样需要分发知识能力的一种类似情况。网格计算也可以解决这些需求,这是由于在 Web 服务标准的推动下,业务过程和事务的集成的重要性继续提高。随着商业网格计算的继续采用,(例如由 Global Grid Forum(即 GGF)之类的组织提出)标准会使从实际需求到商业应用程序都会受益。
目前,网格计算从学术界基于标准的技术的早期界定和开发中获益良多,这些标准可以满足商业业务所需要的更实际、更稳健的实现需求。我们没有理由去猜测这种协同趋势会随着网格计算的不断成熟而没落。
网格填充了一个重要的空白
在过去几年中,网格处理能力(网格每秒可以处理的位数)和微处理器的速度(它依赖于每个集成电路中晶体管的数量)之间出现了一个巨大的差距,如图 1 所示。 图 1. 摩尔定律与存储发展、光纤发展的比较
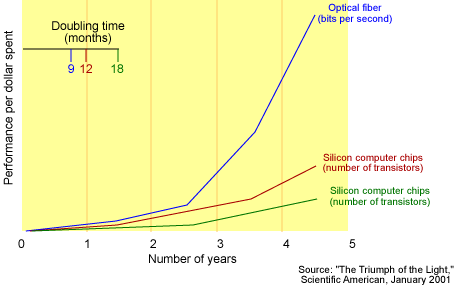
正如图中所示的一样,网络处理能力现在每 9 个月就会翻一倍,而在历史上这种增长曾经一度非常缓慢。摩尔定律指出每个集成电路中晶体管中的数量每 18 个月就会翻一倍。这样就出现了一个问题。与网络能力的发展相比,处理器的发展速度(摩尔定律)要慢很多。
如果您接受这样一个前提:关键的网络技术现在正以比微处理发展速度更快的速度发展,为了利用网络的优点,我们需要另外一种更有效利用微处理器的方法。这个新观点改变了历史上网络与处理器成本之间的平衡。类似的讨论同样适用于存储设备。
网格计算就是解决这种差距的手段,它通过将分布式资源绑定在一起构成一个单一的虚拟计算机从而改变了资源之间的平衡。这个资源丰富的虚拟计算机以及应用程序加速所带来的优点(从几周变成几天,从几天变成几小时,从几小时变成几分钟,依此类推)为商业业务逻辑提供了一个诱人的前景(不过这也可能会需要在通信业务实践中作出重大的变化,以价格变化最为突出)。
现在我们已经介绍了网格计算的起源,并给出了一个例子来证明它的重要性,接下来我们将对其与其他分布式计算概念(集群计算、CORBA、DCE 和 P2P)进行比较,这样就可以强化我们的网格知识基础。
网格与集群计算的区别
集群计算实际上不能真正地被看作是一种分布式计算解决方案。不过对于理解网格计算与集群计算之间的关系是很有用的。通常,人们都会混淆网格计算与基于集群的计算这两个概念,但实际上这两个概念之间有一些重要的区别。
网格是由异构资源组成的。集群计算 主要关注的是计算资源;网格计算 则对存储、网络和计算资源进行了集成。集群通常包含同种处理器和操作系统;网格则可以包含不同供应商提供的运行不同操作系统的机器。(IBM、Platform Computing、DataSynapse 和 United Devices 提供的网格工作负载管理软件都可以将工作负载分发到类型和配置不同的多种机器上。)
网格本质上就是动态的。集群包含的处理器和资源的数量通常都是静态的;而在网格上,资源则可以动态出现。资源可以根据需要添加到网格中,或从网格中删除。
网格天生就是在本地网、城域网或广域网上进行分布的。通常,集群物理上都包含在一个位置的相同地方;网格可以分布在任何地方。集群互连技术可以产生非常低的网络延时,如果集群距离很远,这可能会导致产生很多问题。
网格提供了增强的可扩展性。物理临近和网络延时限制了集群地域分布的能力;由于这些动态特性,网格可以提供很好的高可扩展性。
例如,最近 IBM、United Devices 和多个生命科学合作者完成了一个设计用来研究治疗天花的药品的网格项目。这个网格包括大约两百万台个人计算机。使用常见的方法,这个项目很可能需要几年的时间才能完成 —— 但是在网格上它只需要 6 个月。设想一下如果网格上已经有两千万台 PC 会是什么情况。极端地说,天花项目可以在分钟级内完成。
集群和网格计算是相互补充的。很多网格都在自己管理的资源中采用了集群。实际上,网格用户可能并不清楚他的工作负载是在一个远程的集群上执行的。尽管网格与集群之间存在很多区别,但是这些区别使它们构成了一个非常重要的关系,因为集群在网格中总有一席之地 —— 特定的问题通常都需要一些紧耦合的处理器来解决。
然而,随着网络功能和带宽的发展,以前采用集群计算很难解决的问题现在可以使用网格计算技术解决了。理解网格固有的可扩展性和集群提供的紧耦合互连机制所带来的性能优势之间的平衡是非常重要的。
网格还是 CORBA?
对于所有的分布式计算环境来说,CORBA 与网格计算表面的相似性可能比其他技术都要多。这是由于开放网格服务架构(OGSA)中网格计算和 Web 服务之间的策略关系所决定的。它们都是基于面向服务架构(SOA)的概念。CORBA 是很多任务关键的应用程序的骨干,从 1991 年创建以来不断发展成熟。在很多方面,CORBA 都是今天 Web(网格)服务的先驱。它提供了一个重要的基础,就像是几年之后 Java™ Remote Method Invocation(RMI)的地位一样。
例如,Boeing 在自己的 DCAC/MRM(Define and Control Airplane Configuration/Manufacturing Resource Management 的缩写)应用程序中使用了基于 CORBA 的解决方案,尤其是管理商业飞机所采用的零部件配置和目录部分的应用程序更是如此(喷气式客机有很多零部件)。Peter Coffee 是 e-Week 的一名技术编辑,他最近分析说新 Cunard Queen Mary 2 远洋航线中所有的操作都是由 CORBA 支持的。
CORBA 与网格计算之间的主要区别是 CORBA 假定是面向对象的(毕竟,这是名字中的一部分),但是网格计算没有采用这种假定。在 CORBA 中,每个实体都是一个对象,可以支持诸如继承和多态之类的机制。在 OGSA 中,存在一些与对象非常类似的概念,但是这并没有假定架构中有面向对象的实现。架构是面向消息的;面向对象是一个实现概念。然而,在 WSRF(Web Services Resource Framework)中使用形式定义语言(例如 WSDL,Web Services Definition Language)就意味着接口和交互操作都与 CORBA 中的定义一样,它们共享一个主要软件工程的优点,同时可以采用面向对象的设计呈现。
另外一点区别是网格计算(OGSA)是在 Web 服务的基础上进行构建的。CORBA 与 Web 服务进行了集成,并与 Web 服务进行交互操作。CORBA 的一个问题是它假设了太多的 “端点”,这通常是参与 CORBA 环境的所有机器(客户机和服务器)。供应商的 CORBA 实现中也存在交互操作的问题,CORBA 节点之间在 Internet 上如何操作的问题,以及端点如何命名的问题。这意味着所有的机器都必须遵守特定的规则和特定的方法,只有这样 CORBA 才能正常工作(所有这些都假设采用与 IDL、IOR 和 IIOP 类似的协议)。在构建高可用、紧耦合、预编译的系统时,这是一种比较合适的方法。
然而,在 CORBA 执行作业的方式和 Internet 方法之间缺少协作能力。CORBA 的确为 Web 服务标准的创建提供了灵感 —— 人们非常喜欢 CORBA 基础所提供的功能,并开始建立诸如 XML、WSDL、SOAP 之类的标准。他们通过在开放的 Internet 基础上构建 Web 服务对 CORBA 的交互操作能力和灵活性问题进行了改进,这种方法在服务请求者和服务之间采用的是松耦合和延后绑定技术。为了实现这种改进,OGSA 增加了一种 “软状态” 方法来进行容错。这些正是它们的设计目标。
Web 服务架构是一个面向服务的架构,CORBA 也是。不过 CORBA 的目标不同 —— 它被设计用来构建相当封闭的集成系统。
DCE 如何?
顾名思义,分布式计算环境(DCE)与其说是一个架构,还不如说是一个环境,二者之间有一个重要的区别。DCE 可以定义为一个设计用来促进分布式计算的紧密集成的技术集;网格计算(以 OGSA 的格式)不仅仅是一个设计用来封装分布式计算众多复杂机制的架构。
正如我们在对 CORBA 的介绍中看到的一样,在 DCE 中我们也可以看到紧耦合与松耦合方法之间的区别。DCE 技术包括安全性技术(DCE ACL 或 Access Control Lists)、对象和组件技术(DCE 分布式对象)、文件系统(DFS 或 Distributed File System)以及一个目录定义(DCE 注册项) —— 实际上,OGSA 可以在很多 DCE 技术基础上工作。
例如,网格安全协议可以采用 GSI(Grid Security Infrastructure)格式,也可以采用适当的 Web 服务标准格式,可以用来与 DCE ACL 进行交互。很多网格应用程序都利用底层的 DFS(或其前辈 AFS,Andrew File System)。核心网格注册服务可以利用 DCE 注册项。
尽管这些技术大部分都被认为是服务,但是 DCE 与其说是一个面向服务的架构,还不如一组技术的集合。它对于 SOA 环境中构建应用程序的支持是有限的,因为 DCE 主要是通过采用一些块来构建分布式应用程序,但是并不需要去构建分布式的面向服务的应用程序。
网格计算与 DCE 之间另外一点重要的区别也与 CORBA 有关:OGSA 网格计算定义了以下 3 类服务:
网格核心服务
网格数据服务
网格程序执行服务
CORBA、DCE 和 Java RMI 并不会特别关注数据(DFS 之外的数据)或程序执行服务,因为这些技术都是远程过程调用(RPC)系统所必需的。(RPC 是一种协议,应用程序可以使用这种协议向网络中另外一台机器上的一个程序请求提供服务,而无需理解网络的详细信息。这是一个同步 操作,需要请求程序一直挂起等待远程过程返回结果,除非您使用了共享相同地址空间的轻量级进程(lightweight processe)。在网格核心服务(以及 WSRF)中定义和实现的很多服务都与 DCE 和 CORBA 中的基本服务类似。但是数据和程序执行服务是网格计算所特有的。
最后,我们对网格计算和 CORBA 与 Web 服务标准的关系所总结的区别也同样适用于 DCE。同样,我们在 Web 服务中所看到的很多改进都得益于使用诸如 DCE 和 CORBA 之类优秀分布式系统的经验。
最后来看一下 P2P
诸如 KaZaA —— 由于一些版权问题,它总是以大字标题的形式出现 —— 之类的应用程序是最近吸引人们对点对点(P2P)计算的注意的主要原因。不过这种技术本身展示了一些有趣的分布式特性,如果在网格环境中使用这些特性,很多都会非常有用。
首先,P2P 系统的特点是缺少集中管理点;这使它非常适合于提供匿名服务,或者提供一些反跟踪保护机制。另一方面,网格环境通常都有某种形式的集中管理和安全性(例如,资源管理和工作负载调度)。
P2P 环境中这种没有集中点的特性引发了两个重要结果:
P2P 系统的可扩展性通常都比网格计算系统好。即使我们要在响应能力的控制和分布之间达成某种平衡时,网格计算系统也天生不如 P2P 系统的可扩展性好。
P2P 系统容忍单点失效的能力通常比网格计算系统更好。尽管网格比紧耦合的分布式系统的弹性更好,但是网格不可避免地要包含一些可能成为单点故障的关键元素。
这意味着构建网格计算系统的关键是在分散与管理能力之间达成某种平衡 —— 这可不是件简单的事情。
另外,网格计算的一个重要特性是资源都是动态的;在 P2P 系统中,资源的动态性天生就比网格计算系统更好,资源出现和消失的变化比网格中更快。对于 P2P 和网格计算系统来说,分布式资源的利用率是一个主要目标。给定一定的计算资源,这两种系统都可以尽可能地对这些资源进行使用。
这两个系统之间最后一点区别是标准:与网格领域中的标准相比,在 P2P 中通常缺少标准。另外,有了诸如 Global Grid Forum 之类的实体,网格领域就有了一种机制来重新定义现有的标准并建立新标准。
基于网格和 P2P 系统提供的互补优点,我们可以期望这两种方法最终会殊途同归,尤其是当网格达到 “网格间” 的开发阶段时,届时这两种技术都将成为一些公共工具。
充分利用数据
我们已经介绍了网格计算的组件和起源,并解释了它在基于 Web 服务的企业级应用程序中的重要性,并对网格计算与其他 4 种主要分布式计算系统之间的异同进行了简要的分析。
几乎每个组织现在都有很多广泛分布的未用计算能力。虚拟化 —— 网格计算背后的驱动力 —— 可以帮助我们利用这些尚未使用的计算能力,IBM 参与虚拟内存、虚拟存储和虚拟处理器技术已经有很长的时间了。但是它并不仅仅是为客户创建这些技术。
IBM 的 intraGrid 是基于 Globus 的,这是一个研究和开发网格,让 IBM 可以充分利用自己全球的资产进行研究,另外它还为公司内部的开发人员提供了机会来理解企业级规模的网格中的实际问题和管理复杂性。IBM 在公司中还使用了很多个组织网格,包括设计中心为随需应变业务所使用的网格,这使得 IBM 可以像一个实体一样对设计中心进行管理。
在下一篇文章中,我们将介绍网格系统很多重要组件的战略性技术发展方向。网格计算正在通过集成其他补充技术(主要是在自动化领域)进入随需应变和自适应计算环境,从而实现企业级的业务计算。
参考资料
您可以参阅本文在 developerWorks 全球网站上的英文原文。
“The Triumph of the Light” 介绍了光纤的发展如何提供网络功能来满足日益增长的带宽需求。(本文的图 1 就来自这篇文章,该图最初是由 Cleo Vilett 设计的,数据是由 Vinod Khosla、Kleiner、Caufield 和 Perkins 提供的。)
“History of CORBA” 详细介绍了从 1991 年 V1.0 开始的 CORBA 规范的后续版本。
“On Death, Taxes, and the Convergence of Peer-to-Peer and Grid Computing” 对 P2P 和网格计算技术进行了比较,并为这两种技术最终的汇集画了一张路线图。
“开放网格服务体系结构之旅” 介绍了开放源码网格服务架构(OGSA)的目标,这是网格计算背后的骨干。
“Web 服务是CORBA的翻版吗?” 详细介绍了二者之间的区别,并通过案例介绍了 Web 服务在分布式计算中的价值。
CORBA.ORG CORBA 成功案例 提供了一个业界成功案例的清单。
The Globus Alliance 是广泛使用的 Globus Toolkit 的创建者,也是构建网格议程的领袖。
global Grid Forum 是一个基于社区的论坛,有超过 5,000 个研究人员和从业人员,他们正在开发并促进网格技术及其最佳实践。
这篇 IBM 新闻报道 介绍了网格在 IBM、United Devices 和 Accelrys 项目中的角色,它用来辅助一项试图开发一种可以防止天花病毒后期感染药物的全球研究。
请访问 developerWorks 中国网站 网格计算专区,这里有丰富的信息,可以帮助您使用网格计算技术来开发应用程序。
关于作者:
Matt Haynos 是 IBM Grid Strategy and Technology 小组的程序主管,这个小组的总部位于纽约 Somers。他在该小组中负责多项工作,包括与构建 IBM 网格计算业务相关的广泛计划。他在 IBM 的应用程序开发、程序指导和业务开发领域拥有多个技术和管理职位。他拥有罗彻斯特大学的计算机科学/应用数学和认知科学的学士学位,以及佛蒙特大学的计算机科学硕士学位。他与妻子和两个儿子居住在美国康涅狄格州。
订阅:
评论 (Atom)

